
I've onboarded around 10 people to Ocuroot so far, and one of the most common requests has been the ability to visualize a CI/CD pipeline. Being able to see the structure of your deployment workflow without running it would provide a much faster feedback loop, but will require some changes to the Ocuroot SDK.
I recently got the opportunity to present these changes at an infra.nyc event, and this post summarizes that presentation, outlining how I arrived at these changes and how they'll improve the overall experience!
How another platform does it
In a yaml-based CI platform like GitHub Actions, you will often be able to see a graph of your pipeline to help you understand the flow:
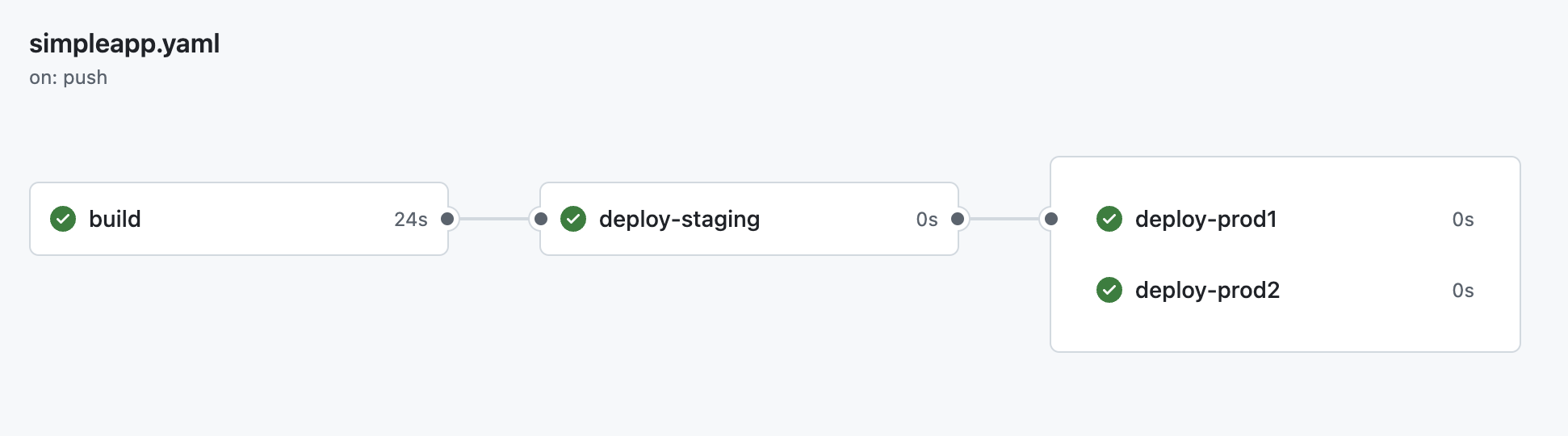
Of course, seeing this pipeline in GitHub requires you to push your change, implying you will be running the steps of your pipeline. This is purely a side effect of GitHub's architecture, though and the shape of the pipeline is rendered as soon as the change is pushed into GitHub. This allows you to track progress in the pipeline as it happens.
This is because dependencies between jobs are defined in the yaml file statically:
deploy-staging:
needs: build
...
deploy-prod1:
needs: deploy-staging
...
Because of these explicit dependencies, you could potentially write a simple tool to render the pre-execution shape of a pipeline directly from the yaml file.
Initially, this is nice and simple to work with and reason about, but add a few pipelines and the process of adding a new environment quickly becomes unwieldly.
Because Ocuroot configuration is written in Starlark, there is a lot more flexibility in defining your pipelines, with a policy function that can adapt to any number of environments of different kinds.
This creates a limitation that you don't have with GitHub's yaml, you can't predict what your pipeline will look like until you run it in it's entirety, since each deploy can impact which environments can be deployed next.
This meant that visualizing pipelines ahead of time was essentially impossible with the existing SDK.
Challenges with the existing SDK
In v0 of the Ocuroot SDK, the policy function was able to determine what actions to perform based on annotations on a build version.
# deploy deploys a build in a given environment
def deploy(ctx):
# ... perform the actual deployment
# Mark this build as staged to allow production deployment
env_type = ctx.environment.attributes.get("type")
if env_type == "staging":
ctx.build.annotations["staged"] = "true"
# policy defines the rules for deploying a build to a given environment
def policy(ctx):
# Prevent deploying to production if not already staged
env_type = ctx.environment.attributes.get("type")
is_staged = ctx.build.annotations.get("staged") == "true"
if env_type == "prod" and not is_staged:
# Don't deploy yet
return later()
# We're ready to deploy!
return ready()
In this example, the policy function depends on the deploy function setting the "staged" annotation to establish
whether you can deploy to production.
The original intention of annotations was to provide a flexible way to control the flow of a pipeline that could be based on any number of inputs. Of course, this meant you wouldn't know what annotations a deploy would deliver until after the deployment was complete.
What was needed was a way to provide the policy function with just enough information to "simulate" a deployment and determine whether it would allow deployment to subsequent environments.
There were a few potential ways to do this. One alternative I considered was to allow users to write "mock" deploy functions that would apply annotations without actually making any changes. A little further down, there was also an option to mock host.shell(...) calls to fake the actual steps of a deployment.
These options essentially put the onus on the end-user to write viable mocks for their pipeline before they could see what the pipeline looked like. Worse, a mistake in writing such a mock could give a false sense of security about what was going to happen.
Instead, I opted to decouple the policy and deploy functions, so you could simulate the deployment flow by just running the policy function and requiring only that deployments succeeded.
Decoupling builds and deployments
This decoupling involved removing the concept of build annotations entirely, and providing the policy function with a list of environments where the build had already been deployed.
def policy(ctx):
# Identify if any staging environments have been deployed
staging_deploys = [x for x in ctx.deployed_environments if x.attributes.get("type") == "staging"]
is_staged = len(staging_deploys) > 0
# Prevent deploying to production if not already staged
env_type = ctx.environment.attributes.get("type")
if env_type == "prod" and not is_staged:
return later()
return ready()
This will need a little syntatic sugar before release, but allows you to define an environment-based pipeline entirely separately from the deployment itself.
Combining this policy function with a set of environments, you can generate a diagram like the below.

This is equivalent to the GitHub example above, but adds explicit "phases" of build and deployment that may contain multiple environments at once.
The Tradeoff
This approach does sacrifice a certain amount of functionality, limiting the ability to use the result of a deployment to directly control the flow of the pipeline. But for most use cases, will allow you to build fairly complex pipeline structures based on the properties of your environments.
More to come!
I'll continue to refine the next version of the SDK to balance fast feedback with functionality and will be posting more updates as I go.
All posts will be shared via LinkedIn and Bluesky. Follow along on your platform of choice!